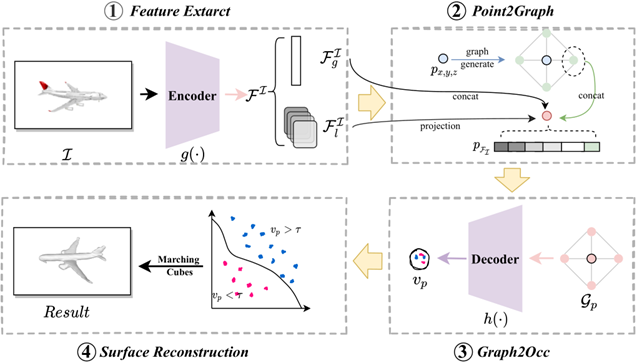
随着虚拟现实、自动驾驶等领域对3D模型需求的激增,传统显式3D重建方法(如体素、点云和网格)在计算资源、细节表现和拓扑灵活性方面存在显著缺陷,隐式表示方法虽克服了显式方法的不足,但仍面临空间信息缺失、先验约束不足和局部细节恢复能力有限等挑战。针对这些问题,本项目提出G2IFu,一种基于图的隐式函数方法,旨在通过引入图结构增强空间感知能力,提升单视图3D重建的精度与细节。项目内容方面,G2IFu通过四个核心模块实现高效重建:特征提取模块采用改进的ResNet-18结合通道与空间自注意力机制,融合图像的全局与局部特征;Point2Graph模块将3D点扩展为包含假设点及其连接关系的图结构,通过投影获取多尺度图像特征;Graph2Occ模块利用图卷积网络(GCN)分析图节点间的空间拓扑关系,预测隐式场状态;表面重建模块通过Marching Cubes算法从预测的隐式场中提取高精度网格。该方法创新性地将图结构引入隐式表示,通过假设点扩展感知范围,并结合自注意力机制优化特征融合。创新点方面,G2IFu首次将图结构整合到神经隐式表示中,通过图节点的空间连接关系捕获局部几何结构,突破了传统点独立预测的局限性;提出基于图的先验边界损失函数,引导网络聚焦于形状表面附近的“关键点”,增强表面细节的恢复能力;设计多尺度特征投影机制与改进的自注意力模块,有效结合全局轮廓信息与局部纹理特征,显著提升复杂几何结构的重建精度。项目成果与指标方面,在ShapeNet数据集上的实验表明,G2IFu在IoU(0.632)、Chamfer-L1(0.159)、EMD(2.899)和F-Score(66.12)等关键指标上均超越现有最优方法(如DISN、ONet),尤其在细节丰富的物体类别(如枪支、灯具)中表现突出,与主流方法相比,G2IFu在保持合理计算资源消耗(参数量14.22M,推理时间1.98秒)的同时实现了更高的重建质量,验证了图结构在隐式场建模中的有效性,此外该方法成功扩展到多视图重建任务,展现了良好的泛化能力。