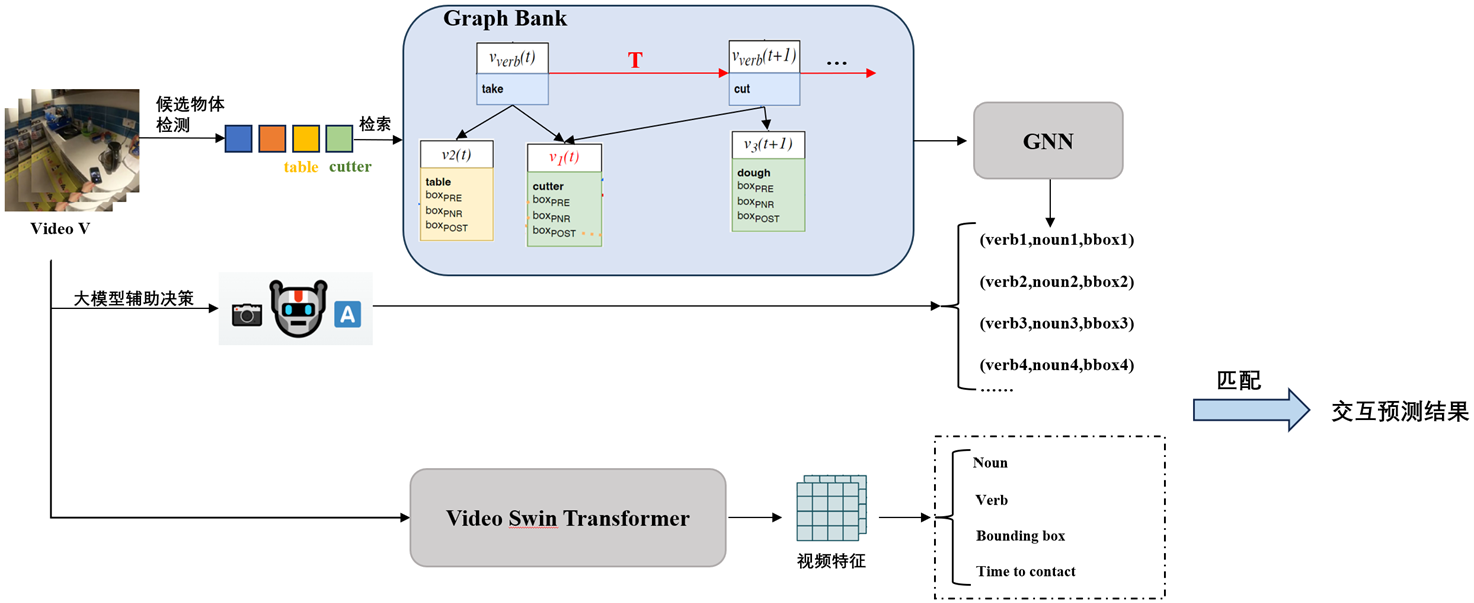
随着计算机视觉和人工智能技术的不断发展,第一人称视频的交互预测任务成为理解人机交互和智能感知的重要研究方向。然而,由于交互行为的复杂性以及长视频信息的冗余和分散性,准确预测下一个交互动作及物体的定位仍面临诸多挑战。针对这一问题,本项目提出了一种基于图神经网络(GNN)的交互建模方法,并引入大模型辅助推理,以提升交互动作的预测精度。此外,提出了“Graph Bank”概念,以实现长视频的结构化存储和高效记忆管理。具体而言,本项目首先利用图神经网络对人与物体的交互动作进行建模,以捕捉复杂的交互关系,从而提高对交互模式的理解能力。在此基础上,结合大模型强大的推理能力,进一步提升对未来交互动作的预测精度,并精确定位交互对象。此外,“Graph Bank”概念的引入,使得长视频能够被分解为语义实体(如场景、物体和动作),并以结构化的方式进行存储和处理,从而提高长视频的分析效率,并支持更精准的交互预测。本项目的创新点在于:1) 采用图神经网络进行交互动作的结构化建模,有效捕捉人与物体之间的复杂关系;2) 结合大模型的推理能力,实现更精准的交互预测和目标定位;3) 提出“Graph Bank”概念,构建高效的长视频记忆存储机制,为长期交互分析提供支持。实验结果表明,所提出的方法在第一人称视频交互预测任务中取得了显著的性能提升。在多个基准数据集上的测试结果显示,该方法在交互预测的mAP指标上相较于现有方法提高了7.8%,物体定位精度提升了6%,有效验证了方法的有效性。该方法为第一人称视频的智能分析提供了新的思路,并为交互预测任务奠定了坚实的基础。