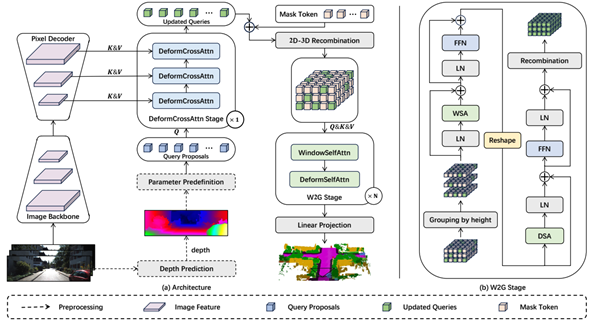
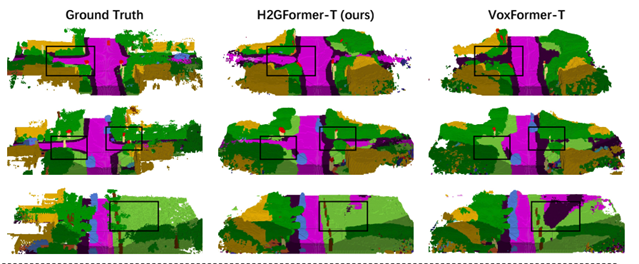
3D语义场景补全(SSC)作为自动驾驶和机器人导航等领域的核心技术,旨在通过稀疏输入(如单目图像或LiDAR点云)预测三维体素的占用状态与语义类别。然而,现有基于Transformer的方法在室外场景中面临显著挑战:一是未充分考虑水平方向相较于垂直方向更高的物体多样性和尺度差异(如道路布局、动态车辆分布),导致长距离上下文建模不足;二是忽略物体边界体素与内部体素的位置重要性差异,造成语义特征扩散效率低下。针对上述问题,本项目提出H2GFormer框架,其核心通过水平到全局的渐进式特征重建机制实现高效语义补全。该方法创新性地设计了水平窗口-全局注意力(W2G)模块,优先沿水平方向扩散可见区域的可靠语义特征,再通过交替的窗口/移位窗口自注意力机制扩展至全局,有效捕捉长距离依赖关系;同时引入内部-外部位置感知损失(IoE-PALoss),基于邻域体素类别变化动态量化边界过渡区域的重要性,强化模型对关键位置的敏感度。在架构层面,采用分层多尺度特征解码策略,结合FPN与可变形交叉注意力模块,逐级提取并融合2D图像的高分辨率特征,提升小物体检测精度。实验表明,H2GFormer在SemanticKITTI数据集上全面超越现有方法:H2GFormer-S版本在51.2m大范围场景的几何补全IoU达44.57%,语义mIoU提升至13.73%;融合多帧输入的H2GFormer-T版本IoU和mIoU分别达到44.69%和14.29%。本项目为室外开放场景的密集三维重建与语义理解提供了创新解决方案,代码已开源以推动相关领域发展。