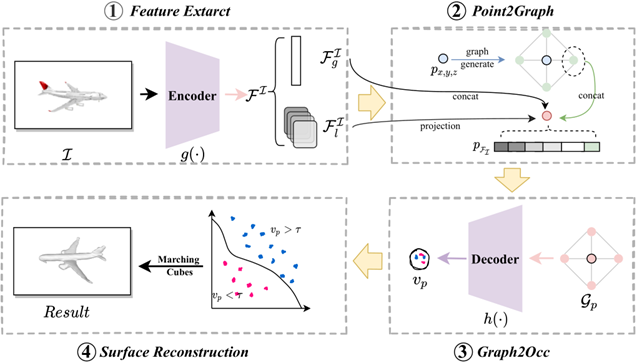
With the increasing demand for 3D models in fields such as virtual reality and autonomous driving, traditional explicit 3D reconstruction methods (e.g., voxels, point clouds, and meshes) face significant limitations in computational resources, detail representation, and topological flexibility. While implicit representation methods have overcome some of these limitations, they still struggle with missing spatial information, insufficient prior constraints, and limited ability to recover local details. To address these challenges, this study proposes G2IFu, a graph-based implicit function method designed to enhance spatial perception and improve the accuracy and detail of single-view 3D reconstruction. The method integrates four core modules for efficient reconstruction: Feature Extraction Module: Combines an improved ResNet-18 with channel and spatial self-attention mechanisms to integrate global and local image features;Point2Graph Module: Expands 3D points into graph structures containing hypothetical points and their connections, obtaining multi-scale image features through projection; Graph2Occ Module: Uses graph convolutional networks (GCNs) to analyze spatial topological relationships between graph nodes and predict implicit field states; Surface Reconstruction Module: Extracts high-precision meshes from predicted implicit fields using the Marching Cubes algorithm. The innovation of G2IFu lies in its integration of graph structures into neural implicit representations, capturing local geometric structures through spatial connections of graph nodes and overcoming the limitations of traditional point-independent predictions. Additionally, the method introduces a graph-based prior boundary loss function to focus on "key points" near shape surfaces, enhancing surface detail recovery. A multi-scale feature projection mechanism and improved self-attention module further combine global contour information with local texture features, significantly improving reconstruction accuracy for complex geometries. The experimental results on the ShapeNet dataset demonstrate that G2IFu outperforms existing state-of-the-art methods (e.g., DISN and ONet) in key metrics such as IoU (0.632), Chamfer-L1 (0.159), EMD (2.899), and F-Score (66.12). Notably, it achieves superior performance in detail-rich object categories (e.g., guns and lamps) while maintaining reasonable computational resource usage (14.22M parameters, 1.98 seconds inference time). The method also shows strong generalization capabilities by successfully extending to multi-view reconstruction tasks.