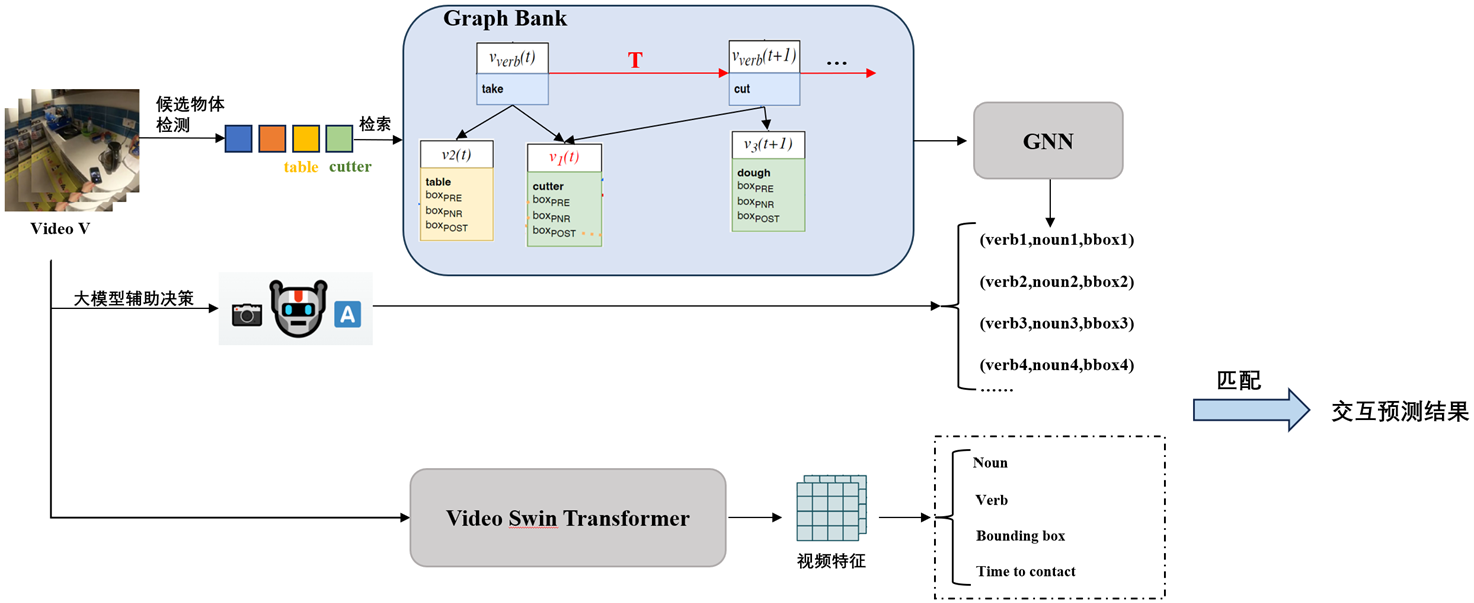
As computer vision and artificial intelligence technologies continue to advance, the task of interaction prediction in first-person videos has become a key research area for understanding human-computer interaction and intelligent perception. However, due to the complexity of interactive behaviors and the redundancy and dispersion of information in long videos, accurately predicting the next interaction and object location remains challenging. To tackle this issue, this project proposes an interaction modeling method based on graph neural networks (GNNs) and introduces large-model-assisted reasoning to enhance the accuracy of interaction prediction. Additionally, the concept of "Graph Bank" is proposed to enable structured storage and efficient memory management of long videos. Specifically, the project first uses GNNs to model human-object interactions, capturing complex relationships to improve the understanding of interaction patterns. Building on this, the powerful reasoning capabilities of large models further enhance the precision of future interaction predictions and object localization. Moreover, the introduction of "Graph Bank" allows long videos to be decomposed into semantic entities (such as scenes, objects, and actions), which are stored and processed in a structured manner. This improves the analysis efficiency of long videos and supports more accurate interaction predictions. The innovations of this project lie in: 1) Using GNNs for structured modeling of interaction actions, effectively capturing complex human-object relationships; 2) Combining the reasoning power of large models to achieve more precise interaction prediction and target localization; and 3) Proposing the "Graph Bank" concept to build an efficient long-video memory storage mechanism, supporting long-term interaction analysis. The experimental results show that the proposed method achieves significant performance improvements in first-person video interaction prediction tasks. Tests on multiple benchmark datasets indicate that this method improves the mean average precision (mAP) of interaction prediction by 7.8% and object localization accuracy by 6% compared to existing methods, effectively validating its effectiveness. This research provides new insights for intelligent analysis of first-person videos and lays a solid foundation for interaction prediction tasks.