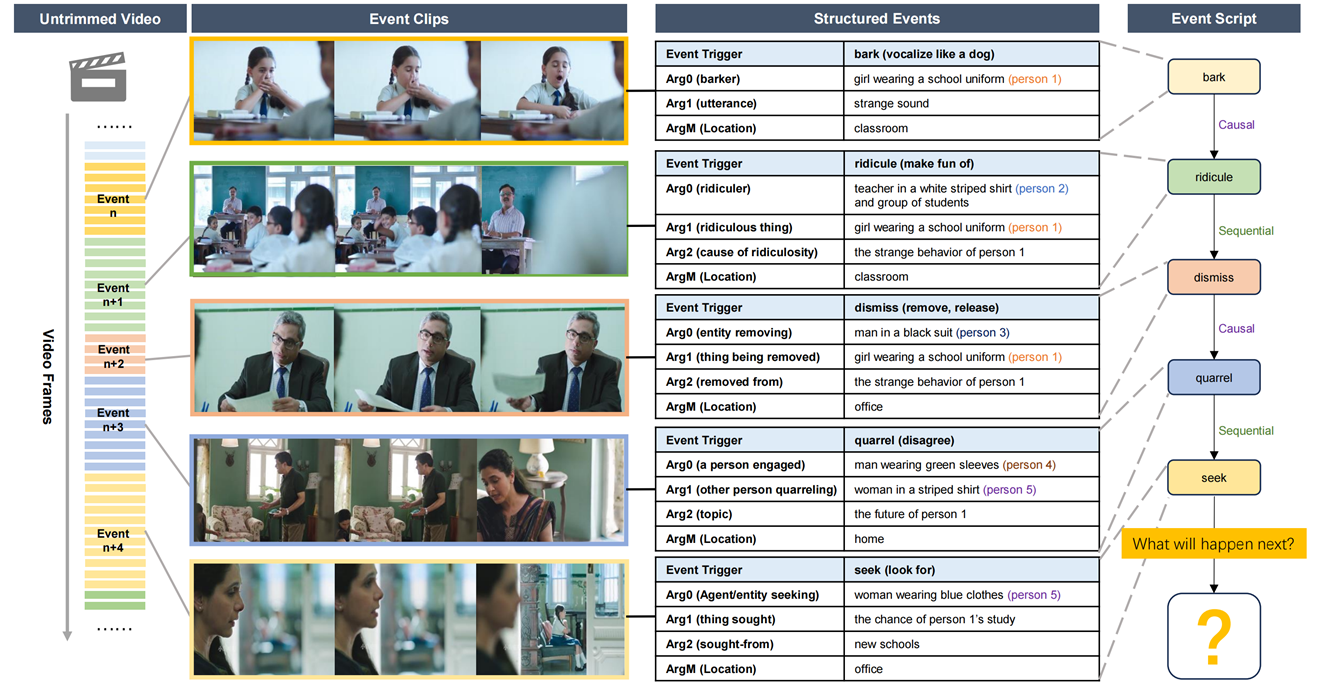
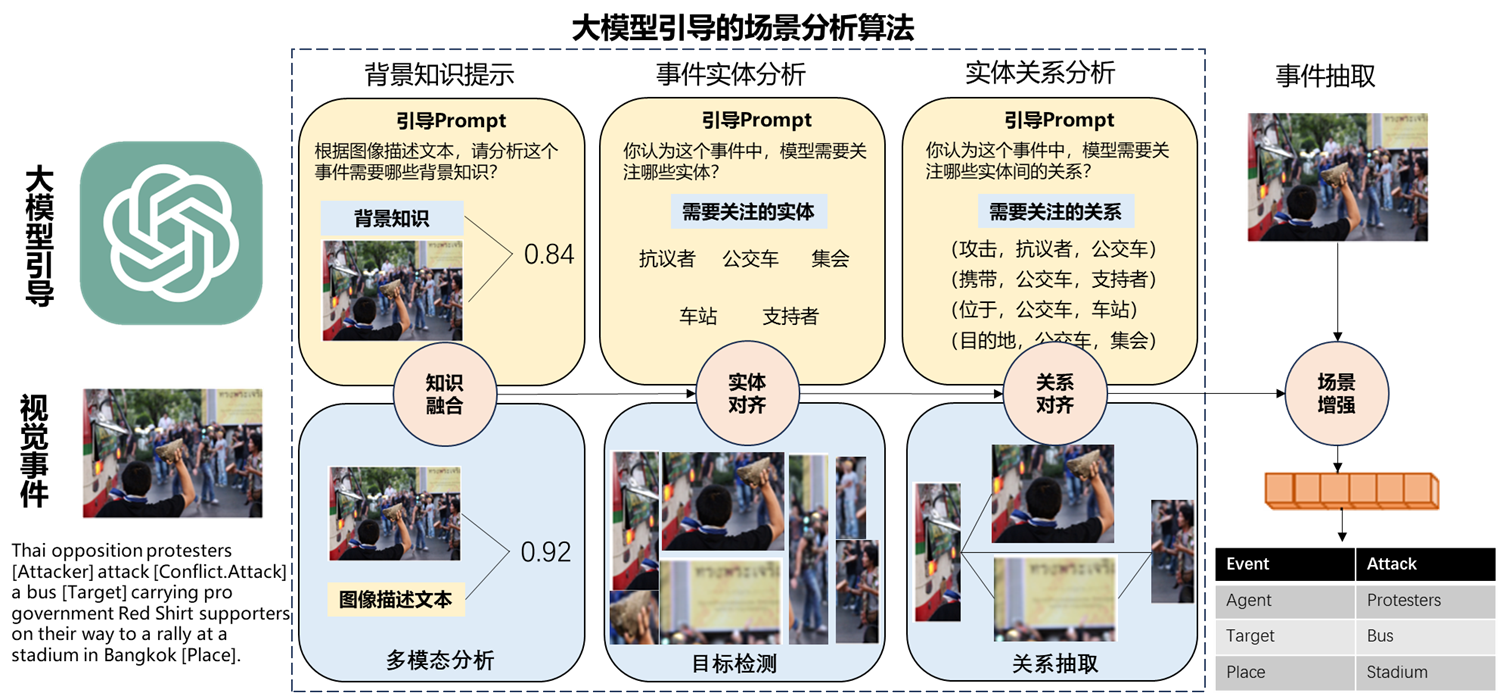
Although visual events significantly impact human cognition, understanding video events remains challenging for artificial intelligence due to their complex structure, multi-layered semantic systems, and dynamic evolution. To address this, our research team proposes a video event understanding task aimed at extracting event scripts from videos and making predictions based on these scripts. To support this task, we have constructed the VidEvent dataset, a large-scale dataset containing over 23,000 finely annotated events. This dataset includes detailed event structures extracted from movie commentary videos, extensive semantic hierarchies, and logical relationships. Through a carefully designed annotation process, we ensure the high quality and reliability of the event data. Additionally, this work provides complete baseline models, with detailed descriptions of their architectures and performance metrics. These models establish benchmarks for future research, facilitating comparisons and improvements. By analyzing the VidEvent dataset and baseline models, this work demonstrates the dataset's potential to advance research in video event understanding and encourages researchers to further explore innovative algorithms and models.