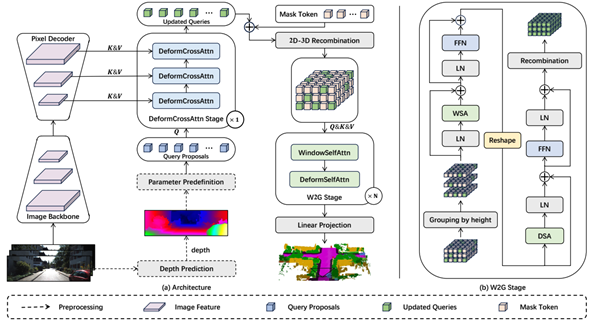
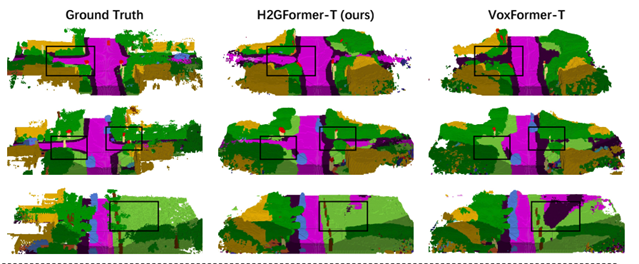
3D semantic scene completion (SSC), a core technology in fields such as autonomous driving and robot navigation, aims to predict the occupancy and semantic categories of 3D voxels using sparse inputs like monocular images or LiDAR point clouds. However, existing Transformer-based methods face significant challenges in outdoor scenarios: first, they fail to adequately consider the higher object diversity and scale differences in the horizontal direction compared to the vertical direction (e.g., road layouts, dynamic vehicle distributions), leading to insufficient long-range context modeling; second, they ignore the difference in positional importance between boundary and internal voxels of objects, resulting in inefficient semantic feature propagation. To address these issues, this study proposes the H2GFormer framework, which achieves efficient semantic completion through a progressive horizontal-to-global feature reconstruction mechanism. The framework innovatively designs a horizontal window-global attention (W2G) module that prioritizes propagating reliable semantic features from visible regions along the horizontal direction, then expands to the global scope via alternating window-shifted window self-attention mechanisms, effectively capturing long-range dependencies. Additionally, it introduces an internal-external position-aware loss (IoE-PALoss) that dynamically quantifies the importance of boundary transition regions based on neighborhood voxel category changes, enhancing the model's sensitivity to critical positions. At the architectural level, a hierarchical multi-scale feature decoding strategy is adopted, combining feature pyramid networks (FPN) with deformable cross-attention modules to progressively extract and fuse high-resolution features from 2D images, improving the detection accuracy of small objects. Experiments show that H2GFormer comprehensively outperforms existing methods on the SemanticKITTI dataset: the H2GFormer-S version achieves a geometric completion IoU of 44.57% and a semantic mIoU of 13.73% in large-scale scenes of 51.2m; the H2GFormer-T version, which integrates multi-frame inputs, reaches IoU and mIoU values of 44.69% and 14.29%, respectively. This work provides an innovative solution for dense 3D reconstruction and semantic understanding in outdoor open scenes, and the code has been open-sourced to promote development in related fields.